Implementing a Vectorized Engine in a Distributed Database

This article is written by Qu Bin, a tech expert at OceanBase. Qu Bin has years of experience in the database industry and he had worked on column-oriented and time-series database kernel development. Currently, he is mainly working on vectorized engine development.
This article introduces the value, design, and technical solutions of vectorized engines from the following three aspects:
- What is vectorized engine?
- Why vectorized engine?
- Implementing a vectorized engine
Background
When talking to customers, we found that many users want to perform OLAP tasks such as JOIN queries and aggregate analysis while they are processing online transactions. The SQL execution engine of a database must be highly productive in order to deal with OLAP tasks, which often involve the processing of massive data and complicated computing and queries, and are therefore time-consuming.
We used to use parallel execution to evenly share workloads among multiple CPU cores in the database’s distributed architecture and successfully cut the query response time (RT) by reducing the amount of data processed by each CPU core. As the user data builds up, the workload of each CPU also increases, if no computing resources are added. On-site investigations indicate that the CPU utilization approximates 100% in some OLAP tasks, such as aggregate analysis and JOIN queries when massive data is involved.
To improve single-core processing performance and reduce response time, we have designed a vectorized query engine from scratch.
What is Vectorized Engine?
The concept of the vectorized engine was introduced in a 2005 paper titled “MonetDB/X100: Hyper-Pipelining Query Execution”. Prior to the vectorized engine era, the volcano model was widely adopted in the database industry.
Originally known as the iterator model, the volcano model was formally introduced in the 1994 paper “Volcano — An Extensible and Parallel Query Evaluation System”, and was adopted by many early versions of mainstream relational databases at that time.
In the early years of database technologies, when database I/O was slow and memory and CPU resources were expensive, database experts developed the classic volcano model, which allows an SQL engine to compute one data row at a time to avoid memory exhaustion.
Although the volcano model has been widely applied, its design does not bring out the full potential of CPU performance. And it often causes data congestion during complex queries such as JOIN queries, queries with subqueries, and queries containing the ORDER BY keyword.
In the paper “DBMSs On A Modern Processor: Where Does Time Go?”, the authors have minutely dissected the resource consumption of database systems in the framework of modern CPUs.
The following figure clearly shows that the CPU time for computation is not greater than 50% in sequential scans, index-based scans, and JOIN queries. On the contrary, the CPU spends quite an amount of time (50% on average) waiting for resources, due to memory or resource stalls. Plus the cost of branch mispredictions, the percentage of CPU time for computation is often far less than 50%. For example, the minimum percentage of CPU time for computation in index-based scans is less than 20%.

Unlike the traditional volcano model which iterates data row by row, the vectorized engine adopts vector iteration to pass multiple rows of data at a time from one operator to another.
In other words, vectorization makes a great leap from single-cell operations to vector operations.
Why Vectorized Engine?
There are two advantages of the vectorized engine.
1. A cache-friendly method that returns vector data with fewer function calls
To further improve CPU utilization and reduce the memory/resource stalls during SQL execution, vectorized engines are introduced and applied to the design of modern databases.
Similar to the traditional volcano model, a vectorized engine also pulls data from the root node of an operator tree. The difference is that the vectorized engine passes vector data at a time and keeps the data as compact as possible in the memory, rather than calling the next() function to pass one row at a time. Since the data is contiguous, the CPU can quickly load the data to the level-2 cache (L2 cache) by instruction prefetching, which reduces memory stalls and thus improves CPU utilization. The contiguous and compact data in the memory also make it possible to process a set of data at a time by running a SIMD instruction. This brings the computing power of modern CPUs into full play.
The vectorized engine drastically reduces the number of function calls. Assuming that you want to query a table of 100 million rows of data, a database of the volcano model must perform 100 million iterations to complete the query. If you use a vectorized engine and set the vector size to 1024 rows, the number of function calls to execute the query is significantly reduced to 97,657, which is calculated by dividing 100 million by 1024. Inside an operator, the function crunches a chunk of data by traversing the data in a loop instead of nibbling one row at a time. Such vector processing of contiguous data is more friendly to the dCache and iCache of CPUs and reduces cache misses.
2. Higher CPU capabilities to process an instruction stream with fewer branch predictions
The paper “DBMSs On A Modern Processor: Where Does Time Go?” also indicates that branch mispredictions have a serious impact on the database performance because the CPU halts the execution of an instruction stream and refreshes the pipeline upon a misprediction. The paper “Micro Adaptivity in Vectorwise” released at the 2013 ACM SIGMOD Conference on Management of Data (SIGMOD’13) also elaborates on the execution efficiency of branching at different selectivities. A figure is provided below for your information.
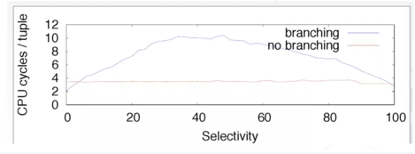
The logic of the SQL engine of a database is complicated. Therefore, conditional logic is inevitable for the volcano model. In contrast, the vectorized engine can keep conditionals at the minimum in an operator. For example, the vectorized engine can avoid an IF statement within a FOR loop by overriding data writes by default, thus protecting the CPU pipeline from branch mispredictions and greatly improving CPU capabilities.
3. Faster computation accelerated by SIMD instructions
The vectorized engine handles contiguous data in the memory, hence can easily load a set of data into a vector register. It then sends a single instruction, multiple data (SIMD) instruction to perform vector computation instead of using the traditional scalar algorithm. Note that the SIMD instruction is closely related to the CPU architecture, and corresponding instruction sets are provided for x86, ARM, and PPC architectures. At present, the Intel x86 architecture supports the most instructions. The figure below shows SIMD instructions for the x86 architecture and the data types that each instruction supports. For more information, see the official manual of Intel.

Implementing a Vectorized Engine in OceanBase
This section details the implementation of the OceanBase vectorized engine from the following aspects: storage, data organization, and SQL operators.
Storage Vectorization
OceanBase Database stores data in microblocks, the minimum unit of I/O operations. The size of each microblock is 64 KB by default and can be resized.
In each microblock, the data is stored in columns. During a query, sets of data in a microblock are projected to the memory of the SQL engine by columns. Thanks to the compact structure, the data can be easily cached, and the projection process can be accelerated by using SIMD instructions. Since the vectorized engine does not maintain physical rows, it fits well with the data storage mode in a microblock. This makes data processing simpler and more efficient. The data storage and projection logic is illustrated in the following figure.
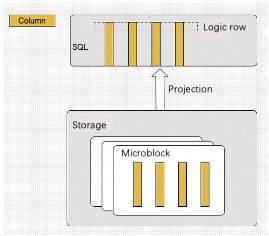
Data Organization in a Vectorized SQL Engine
Memory orchestration
In the SQL engine, all data is stored in expressions. Expressions are managed by a Data Frame, a contiguous piece of memory of no more than 2 MB in size. In other words, Data Frame holds the data of all expressions involved in SQL queries, and the SQL engine allocates the required memory from the Data Frame.

In a non-vectorized engine, an expression processes only one row of data cells at a time, as shown in the left part of the above figure. In a vectorized engine, an expression stores multiple rows of compactly structured data cells, as shown in the right part of the above figure.
This way, the data in an expression is computed as a vector, which is more friendly to the CPU cache. The compact data structure also allows easy computation acceleration by using SIMD instructions.
In addition, the number of cells allocated to each expression, or the vector size, can be adjusted based on the size of the L2 cache of the CPU and the number of expressions in an SQL statement. The principle of vector resizing is to ensure that all cells involved in the computation are stored in the L2 cache of the CPU to reduce the impact of memory stalls.
Design of filter representations
The filter representations of vector engines need to be redesigned. This is because a vector engine returns vector data at a time, and only a part of the data is output. Other data is filtered out. It is important to efficiently identify the data to be output or the valid data. The paper “Filter Representation in Vectorized Query Execution” compares the following two common strategies in the industry:
- Identifying rows by bitmaps. In this strategy, a bitmap is created to include a number of bits that equals the size of the returned data vector. The bit of a valid row is set to 1, whereas the bit of an invalid row is set to 0.
- Recording valid rows by using an additional selection vector. In this strategy, the subscripts of valid rows are stored in a selection vector.
OceanBase Database uses the bitmap strategy because, among other advantages, it occupies a small memory space. This prevents the out-of-memory (OOM) error especially when a query involves too many operators or extra-large vectors.
The data identified by a bitmap is sparse when the data selectivity is low, which may lead to unsatisfactory performance. Some databases tackle this by adding sorting methods to densify the data. However, we have found in practice that the SQL execution under HTAP workloads often involves blocking operators, such as Sort, Hash Join, and Hash Group By, or transmission operators. These operators intrinsically output dense data. Extra data sorting only causes unnecessary overheads. Therefore, the OceanBase vectorized engine does not provide a method to modify the bitmap structure.
Implementing Operators in a Vectorized Engine
The vectorization of operators is an essential part of the OceanBase vectorized engine. To support the vectorized engine, all query operators are redesigned to fit its characteristics. In accordance with the working principles of the vectorized engine, each operator fetches vector data from the lower-level operator through the vector interface, and the data in each operator is engineered by following guidelines such as branchless programming, memory prefetching, and SIMD instructions. This allows the database to maximize performance improvement. As a large number of operators are involved, I would like to take Hash Join and Sort Merge Group By as examples.
Hash Join
Hash Join implements a Hash lookup of two tables, say tables R and S, by creating and probing a Hash table. When the Hash table is larger than the L2 cache of the CPU, the random access of the Hash table will cause memory stalls and greatly reduce the execution efficiency. Therefore, cache optimization is an important part of Hash Join vectorization, where the impact of cache misses on performance is addressed as a top priority.
It is worth mentioning that the vectorized Hash Join operator of OceanBase Database does not implement hardware-conscious Hash Joins such as Radix Hash Join. Cache misses and memory stalls are avoided by vector-based Hash value computation and memory prefetching.
Radix Hash Join effectively reduces the cache and Translation Lookaside Buffer (TLB) misses, but it needs to scan table R twice and incurs the cost of creating histograms and additional materialization. The vectorization of Hash joins is more streamlined in OceanBase Database. First, a Hash table is created based on the partitions of tables S and R. At the Hash table probe operation, the vectorized Hash value is first obtained by vector computation. Then, the data in the Hash bucket corresponding to that vector is prefetched and loaded into the CPU cache. Finally, the results are compared based on the Join conditions. By controlling the vector size, it is ensured that the prefetched vector data can be loaded into the L2 cache of the CPU. This way, cache misses and memory stalls can be kept at a minimum during data comparison, thereby improving CPU utilization.
Sort Merge Group By
Sort Merge Group By is a common aggregation operation. It sorts the data in order, uses the Group By operator to find the grouping boundaries based on data comparison, and then computes the data in the same group.
For example, the data in column c1 is ordered, as shown in the figure below.
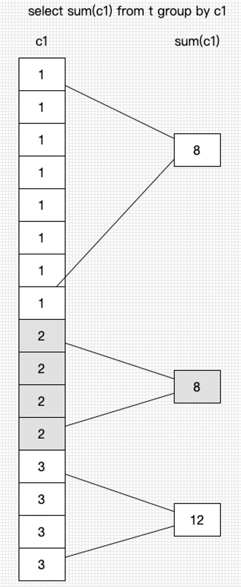
In the volcano model that iterates only one data row at a time, eight comparisons are required for Group 1, and sum(c1) needs to perform eight additions to get the result.
The vectorized engine performs the comparison and aggregation separately. In other words, it first performs eight comparisons to determine the number of data rows in Group 1. As the data values in the group are the same, sum() and count() can be further optimized. In this example, sum(c1) can be performed by 1 x 8, and count(c1) can be directly added by 8.
In addition, vectorization can also speed up computation by introducing methods such as dichotomization. Assuming that a 16-row vector is defined for column c1 in the figure above. Under the dichotomization strategy, the engine takes the first step of 8 rows to compare the data from row 0 to row 7. If the data is equal, it sums up the first 8 data rows. In the second step of 8 rows, the engine compares the data from row 7 to row 15. If the data are not equal, it goes back by 4 rows and compares the data again, until it finds the grouping boundary. After that, the engine repeats the preceding steps to find the next grouping boundary. Under the dichotomization strategy, duplicate data can be skipped during comparison, which predicates faster computation. Dichotomization delivers poor performance if the column contains few duplicate data. We can decide whether to enable dichotomization during the execution based on statistics such as the number of distinct value (NDV).
The OceanBase vectorized engine is under constant upgrade. For example, the current SIMD instructions of OceanBase Database are written for the AVX-512 instruction set, which is applicable to the x86 instruction set architecture. With the increase of ARM-based applications, we will provide SIMD instructions for ARM-based systems. Furthermore, as a lot of operators can be optimized to support the vectorized engine, the OceanBase team will continue to work on this and integrate more new operators and technical solutions with the vectorized engine to better support users in their businesses.
