Data Compression Technology Explained: Balance between Costs & Performance
With more and more data being generated, storage and maintenance costs are increasing accordingly. Data compression seems to be a natural choice to reduce storage costs.
However, there is a dilemma when it comes to the data compression ratio. If the ratio is high, it usually takes a great deal of time to compress and decompress data, which tends to reduce the I/O performance of the memory and disk and is not a good idea for a latency-sensitive key business. If the ratio is low, the compressed files still occupy a large share of disk space, which makes the compression ineffective.
A high compression ratio doesn’t necessarily make sense
Most database products on the market provide data compression features. However, compression design and performance vary based on the storage engine architecture and database application scenarios.
Generally, conventional transactional databases store data in fixed-length blocks, which is good for read/write performance but causes additional overhead and space waste.
Databases oriented to online transaction processing (OLTP) must support higher transactions per second (TPS) during data write and update operations. Such databases often use row-oriented B-tree storage engines and therefore are more conservative on data compression. A B-tree storage engine usually aligns the size of a fixed-length data node with that of a persistent data block for data management. In some cases, updated data should be written to data blocks in real-time, which leads to the compression of the whole data node even if the DML operations affect only a few rows in the node, bringing more overhead. Besides, the compression of fixed-length data blocks also causes a waste of storage space because it is difficult to predict the post-compression size of a data block.
Analytical databases, however, are naturally more suitable for high-ratio compression but are not good for query and update performance.
For systems oriented to online analytical processing (OLAP), such as a data warehouse, data is usually imported by batch, with little incremental data. Therefore, analytical databases usually use column-oriented storage engines that write logs for incremental data and update baseline data periodically. Such storage engines tend to perform data compression during batch import and data updates in the background, based on compression strategies that aim for a higher compression ratio. For example, a column-oriented storage engine will compress more data into larger data blocks, store the data of the same column in adjacent data blocks, and then encode the data based on the data characteristics of the column to achieve a higher compression ratio. However, the compression may significantly reduce the performance of point queries and decrease the TPS of data updates.
In short, the higher the compression ratio, the higher the compression and decompression overhead, leading to a greater impact on performance. We found that users are more concerned about database performance than the compression ratio, especially when it comes to critical business. Given that compressing or decompressing data while it is being read or written inevitably consumes computing resources and affects the transaction processing performance, a conventional business database only supports compression of cold data such as archives or backups. Hot data that is frequently queried or updated cannot be compressed for the sake of business performance.
A high compression ratio makes sense for user benefits only when high database performance is guaranteed in the first place. That way, we can improve the business efficiency at lower costs.
A new solution from OceanBase: Encoding and compression
Compression does not consider data characteristics, while encoding compresses data by column based on data characteristics. These two types of methods are orthogonal, meaning that we can first encode a data block and then compress it to achieve a higher compression ratio.
At the stage of compression, OceanBase Database uses compression algorithms to compress a microblock, without considering the data format, and eliminate data redundancy if detected. OceanBase Database supports compression algorithms like zlib, Snappy, zstd, and LZ4. In most cases, Snappy and LZ4 are faster but provide lower compression ratios. LZ4 is faster than Snappy in terms of both compression and decompression. Both zlib and zstd deliver higher compression ratios but are slower, with zstd being faster in decompression. You can use DDL statements to configure and change the compression algorithms for tables based on table application scenarios.
Before data is read from a compressed microblock, the whole microblock is decompressed for scanning, which causes CPU overhead. To minimize the impact of decompression on query performance, OceanBase Database assigns the decompression task to asynchronous I/O threads, which will call the callback function to decompress the microblock when the I/O operations on the microblock are finished and then store the decompressed microblock in the block cache as needed. This, combined with query prefetching, provides a pipeline of microblocks for query processing threads and eliminates the additional overhead due to decompression.
The advantage of compression is that it makes no assumptions about the data to compress and can always find a pattern for any data and then compress it. A relational database has more prior knowledge about the structured data stored in it. We believe that we can make use of the prior knowledge to improve data compression efficiency.
Encoding algorithms in OceanBase Database
To achieve a higher compression ratio and help users reduce storage costs, OceanBase Database has developed a variety of encoding algorithms that have worked well. In addition to single-column encoding algorithms, such as bit-packing, Hex encoding, dictionary encoding, run-length encoding (RLE), constant encoding, delta encoding for numeric data, and delta encoding for fixed-length strings, OceanBase Database also provides innovative column equal encoding and column prefix encoding to compress different types of redundant data in one or several columns, respectively.
- Bit-packing and Hex encoding: Reducing bit width for storage
Bit-packing and Hex encoding are similar in that they represent the original data by encoding it with fewer bits if the cardinality of data is small. Given an int64 column with a value range of [0, 7], for example, we can store only the lowest three bits to represent the originals and remove higher zero bits to save storage space. Or, for a string column with a character cardinality of less than 17, we can map each character in the column to a hexadecimal number in the range of [0x0, 0xF]. This way, each original character is represented by a 4-bit hexadecimal number, which occupies less storage space. Moreover, these two encoding algorithms are not exclusive, which means that you can perform bit-packing or hex encoding on numeric data or strings generated by other encoding algorithms to further reduce data redundancy.


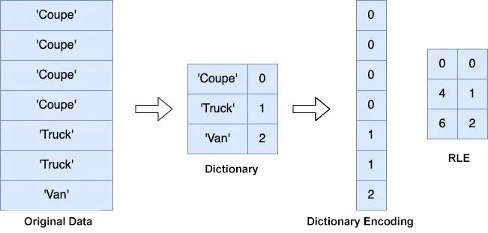
2. Dictionary encoding and RLE: De-duplicating data in a single column
We can create a dictionary for a data block to compress data with low cardinality. If low-cardinality data within a microblock is not evenly distributed, meaning that rows with the same data in a column cluster together, we can also use RLE to compress the reference values of the dictionary. Further, if most of the rows in the microblock of a low-cardinality column have the same value, we can compress the data even more by using constant encoding, which stores the most frequent data as constants and the non-constant data and corresponding row subscripts in an exception list.
3. Delta encoding: Compressing data based on the value range
OceanBase Database supports delta encoding for numeric data and delta encoding for fixed-length strings. Delta encoding for numeric data is suitable for compressing numeric data in a small value range. To compress date, timestamp, or other numeric data of small adjacent differences, we can keep the minimum value, and store the difference between the original data and the minimum value in each row. These differences can usually be compressed by using bit-packing. Delta encoding for fixed-length strings is a better choice for compressing artificially generated nominal numbers, such as order IDs and ID card numbers, as well as strings of a certain pattern, such as URLs. We can specify a pattern string for a microblock of such data and store the difference between the original string and the pattern string in each row to achieve better compression results.


4. Span-column encoding: Reducing redundancy across columns
OceanBase Database provides span-column encoding to improve the compression ratio by making use of the data similarity between different columns. Technically, data is encoded within a column in a column-oriented database. In a real-life business database, however, it’s common that data in different columns to be associated.
- If most data of column A and column B are the same, we can use column equal encoding. In this coding, column A is taken as the reference of column B, and for column B, only rows that are different from those in column A need to be stored.
- If data in column A is the prefix of data in column B, OceanBase Database adopts column prefix encoding. In this encoding, all data in column A and data excluding prefixes in column B are stored.
Span-column encoding performs better in the compression of composite columns and some system-generated data, and can also reduce data redundancy due to inappropriate table design paradigms.
Adaptive compression: Allow the database to select encoding algorithms
The compression performance of data encoding algorithms is related not only to the table schema but also to data characteristics such as the distribution of data and the value range of data within a microblock. This means it is hard to achieve the best compression performance by specifying a columnar encoding algorithm when you design the table data model. To make your work easier and improve the compression performance, OceanBase Database automatically detects the data in all columns and selects an appropriate encoding algorithm for each column during data compaction. The database supports encoding the same column in different microblocks with different algorithms.
The process of detection and selection involves a lot of computing work, which puts more pressure on the CPU during the compaction. Therefore, in a compaction task, OceanBase Database analyzes the data type, value range, number of distinct values (NDV), and other data characteristics and selects a more suitable encoding algorithm by using a heuristic algorithm based on the encoding algorithm and compression ratio selected for the same column in the previous microblock. In addition to selecting a more suitable encoding algorithm, this method ensures acceptable CPU overhead for encoding during the compaction.
One more step: Optimize the query of encoded data
To better balance the compression result and query performance, we have considered the impact on query performance when designing data encoding methods.
- Row-level random access
In compression scenarios, the whole data block will be decompressed even if you want to access just a slice of data in it. In some analytical systems intended for scan queries rather than point queries, patched frame-of-reference (PFOR) delta coding, for example, is adopted to decode adjacent or all preceding rows before accessing a row in a data block.
To better support transactional workloads, OceanBase Database needs to support more efficient point queries. So, our encoding methods ensure row-level random access to encoded data. To be specific, the database accesses and decodes only the metadata of the target row in a point query, which reduces the computational amplification during random point queries. In addition, OceanBase Database stores all metadata required for decoding data in a microblock just within the microblock, so that the microblock is self-describing with better memory locality during decoding.
2. Cache decoder
OceanBase Database initializes a decoder for data decoding of each column. Creating the decoder certainly consumes some CPU and memory resources. To further reduce the response time for accessing encoded data, OceanBase Database caches the decoder and data block together in the block cache. This way, the cached decoder can directly decode the cached data block. The creation and caching of decoders are also executed by asynchronous I/O callback threads to reduce the decoder initialization overhead. When it fails to hit a decoder in the block cache, OceanBase Database also builds a cache pool for the metadata memory and objects required by the decoder, which are reused in different queries.
After those optimizations, even encoded data in SSTables with a hybrid row-column storage architecture can well support transactional workloads.
When it comes to analytical queries, encoded data, which is stored in a hybrid row-column storage architecture, is distributed more compactly and is more CPU cache friendly. These characteristics of encoded data are similar to those of data stored by column, and therefore we can improve analytical queries by applying some optimization methods that often work on columnar storage, such as Single Instruction Multiple Data (SIMD) processing.
Furthermore, since we store dictionaries, null bitmaps, constants, and other metadata in a microblock to describe the distribution of the encoded data, we can use the metadata to optimize the execution of some filter and aggregate operators during a data scan and to perform calculations directly on the compressed data. Many data warehouses use similar approaches to optimize the query execution. In a SIGMOD 2022 paper titled “CompressDB: Enabling Efficient Compressed Data Direct Processing for Various Databases”, authors also describe a similar idea, where the system efficiency is improved by pushing some computations down to the storage layer and executing them directly on the compressed data. The performance turns out to be pretty good.
OceanBase Database significantly strengthened its analytical processing capabilities in V3.2. In the latest versions, aggregation and filtering are pushed down to the storage layer and the vectorized engine is used for vectorized batch decoding based on the columnar storage characteristics of encoded data. When processing a query, OceanBase Database performs calculations directly on the encoded data by making full use of the encoding metadata and the locality of encoded data stored in a columnar storage architecture. This brings a significant increase in the execution efficiency of the pushed-down operators and the data decoding efficiency of the vectorized engine. Data encoding-based operator push-down and vectorized decoding are also important features that have empowered OceanBase Database to efficiently handle analytical workloads and demonstrate an extraordinary performance in TPC-H benchmark tests.
Testing the encoding and compression algorithms
We performed a simple test to see the influence of different compression methods on the compression performance of OceanBase Database.
We used OceanBase Database V4.0 to test the compression ratio with a TPC-H 10 GB data model in transaction scenarios and with an IJCAI-16 Brick-and-Mortar Store Recommendation Dataset in user behavior log scenarios.
The TPC-H model simulated real-life order and transaction processing. We tested the compression ratios of two large tables in the TPC-H model: ORDERS table, which stores order information, and LINEITEM table, which stores product information. Under the default configuration where both the zstd and encoding algorithms were used, the compression ratio of the two tables reached about 4.6 in OceanBase Database, much higher than the compression ratio achieved when only the encoding or zstd algorithm was used.
The IJCAI-16 Taobao user log dataset stored desensitized real behavior logs of Taobao users. The compression ratio reached 9.9 when the zstd and encoding algorithms were combined, 8.3 for the encoding algorithm alone, and 6.0 for the zstd algorithm alone.
As you can see, OceanBase Database works better in real business data compression and also shows an impressive performance on datasets with less data redundancy like the TPC-H model.

This article shares our thoughts and solution for data compression in OceanBase Database. Based on the LSM-Tree storage engine, OceanBase Database has achieved a balance between storage costs and query performance.
If you have any questions, welcome to leave a comment below!